













")














")

New analysis reveals that the way in which AI companies invoice by tokens hides the true value from customers. Suppliers can quietly inflate fees by fudging token counts or slipping in hidden steps. Some techniques run further processes that don’t have an effect on the output however nonetheless present up on the invoice. Auditing instruments have been proposed, however with out actual oversight, customers are left paying for greater than they understand.
In practically all instances, what we as shoppers pay for AI-powered chat interfaces, comparable to ChatGPT-4o, is at present measured in tokens: invisible items of textual content that go unnoticed throughout use, but are counted with actual precision for billing functions; and although every alternate is priced by the variety of tokens processed, the person has no direct solution to affirm the depend.
Regardless of our (at greatest) imperfect understanding of what we get for our bought ‘token’ unit, token-based billing has grow to be the usual method throughout suppliers, resting on what could show to be a precarious assumption of belief.
Token Phrases
A token is just not fairly the identical as a phrase, although it typically performs an identical function, and most suppliers use the time period ‘token’ to explain small items of textual content comparable to phrases, punctuation marks, or word-fragments. The phrase ‘unbelievable’, for instance, could be counted as a single token by one system, whereas one other would possibly break up it into un, believ and in a position, with every bit growing the fee.
This technique applies to each the textual content a person inputs and the mannequin’s reply, with the value primarily based on the overall variety of these items.
The problem lies in the truth that customers don’t get to see this course of. Most interfaces don’t present token counts whereas a dialog is going on, and the way in which tokens are calculated is difficult to breed. Even when a depend is proven after a reply, it’s too late to inform whether or not it was honest, making a mismatch between what the person sees and what they’re paying for.
Current analysis factors to deeper issues: one research reveals how suppliers can overcharge with out ever breaking the principles, just by inflating token counts in ways in which the person can’t see; one other reveals the mismatch between what interfaces show and what’s really billed, leaving customers with the phantasm of effectivity the place there could also be none; and a third exposes how fashions routinely generate inner reasoning steps which can be by no means proven to the person, but nonetheless seem on the bill.
The findings depict a system that appears exact, with actual numbers implying readability, but whose underlying logic stays hidden. Whether or not that is by design, or a structural flaw, the end result is identical: customers pay for greater than they will see, and sometimes greater than they count on.
Cheaper by the Dozen?
Within the first of those papers – titled Is Your LLM Overcharging You? Tokenization, Transparency, and Incentives, from 4 researchers on the Max Planck Institute for Software program Techniques – the authors argue that the dangers of token-based billing lengthen past opacity, pointing to a built-in incentive for suppliers to inflate token counts:
‘The core of the issue lies in the truth that the tokenization of a string is just not distinctive. For instance, take into account that the person submits the immediate “The place does the following NeurIPS happen?” to the supplier, the supplier feeds it into an LLM, and the mannequin generates the output “|San| Diego|” consisting of two tokens.
‘For the reason that person is oblivious to the generative course of, a self-serving supplier has the capability to misreport the tokenization of the output to the person with out even altering the underlying string. As an example, the supplier may merely share the tokenization “|S|a|n| |D|i|e|g|o|” and overcharge the person for 9 tokens as an alternative of two!’
The paper presents a heuristic able to performing this sort of disingenuous calculation with out altering seen output, and with out violating plausibility underneath typical decoding settings. Examined on fashions from the LLaMA, Mistral and Gemma collection, utilizing actual prompts, the strategy achieves measurable overcharges with out showing anomalous:
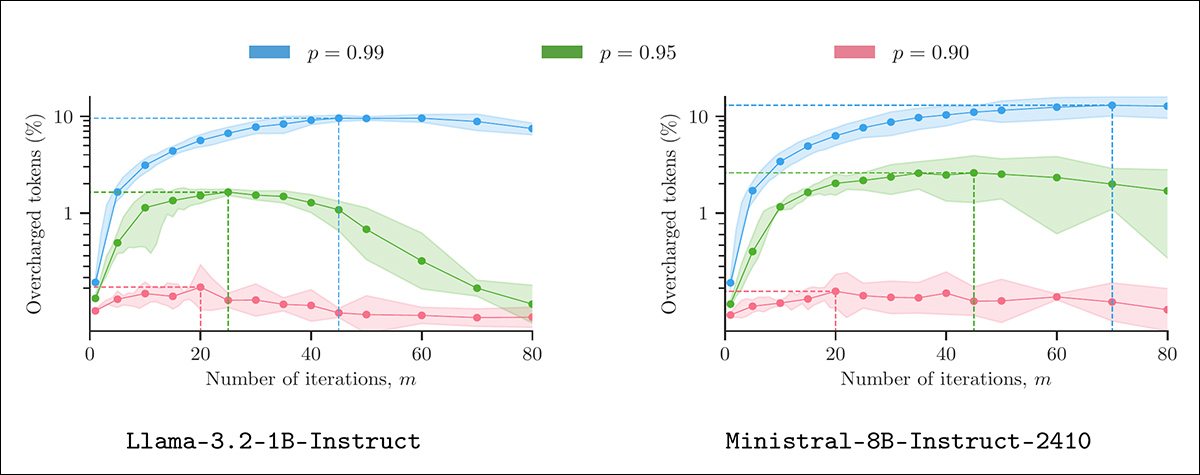
Token inflation utilizing ‘believable misreporting’. Every panel reveals the proportion of overcharged tokens ensuing from a supplier making use of Algorithm 1 to outputs from 400 LMSYS prompts, underneath various sampling parameters (m and p). All outputs have been generated at temperature 1.3, with 5 repetitions per setting to calculate 90% confidence intervals. Supply: https://arxiv.org/pdf/2505.21627
To deal with the issue, the researchers name for billing primarily based on character depend reasonably than tokens, arguing that that is the one method that provides suppliers a purpose to report utilization truthfully, and contending that if the purpose is honest pricing, then tying value to seen characters, not hidden processes, is the one possibility that stands as much as scrutiny. Character-based pricing, they argue, would take away the motive to misreport whereas additionally rewarding shorter, extra environment friendly outputs.
Right here there are a variety of additional issues, nevertheless (usually conceded by the authors). Firstly, the character-based scheme proposed introduces extra enterprise logic that will favor the seller over the buyer:
‘[A] supplier that by no means misreports has a transparent incentive to generate the shortest doable output token sequence, and enhance present tokenization algorithms comparable to BPE, in order that they compress the output token sequence as a lot as doable’
The optimistic motif right here is that the seller is thus inspired to provide concise and extra significant and worthwhile output. In observe, there are clearly much less virtuous methods for a supplier to cut back text-count.
Secondly, it’s affordable to imagine, the authors state, that firms would possible require laws to be able to transit from the arcane token system to a clearer, text-based billing technique. Down the road, an rebel startup could resolve to distinguish their product by launching it with this sort of pricing mannequin; however anybody with a very aggressive product (and working at a decrease scale than EEE class) is disincentivized to do that.
Lastly, larcenous algorithms such because the authors suggest would include their very own computational value; if the expense of calculating an ‘upcharge’ exceeded the potential revenue profit, the scheme would clearly don’t have any advantage. Nevertheless the researchers emphasize that their proposed algorithm is efficient and economical.
The authors present the code for his or her theories at GitHub.
The Swap
The second paper – titled Invisible Tokens, Seen Payments: The Pressing Must Audit Hidden Operations in Opaque LLM Companies, from researchers at the College of Maryland and Berkeley – argues that misaligned incentives in industrial language mannequin APIs usually are not restricted to token splitting, however lengthen to whole courses of hidden operations.
These embody inner mannequin calls, speculative reasoning, software utilization, and multi-agent interactions – all of which can be billed to the person with out visibility or recourse.

Pricing and transparency of reasoning LLM APIs throughout main suppliers. All listed companies cost customers for hidden inner reasoning tokens, and none make these tokens seen at runtime. Prices range considerably, with OpenAI’s o1-pro mannequin charging ten instances extra per million tokens than Claude Opus 4 or Gemini 2.5 Professional, regardless of equal opacity. Supply: https://www.arxiv.org/pdf/2505.18471
In contrast to standard billing, the place the amount and high quality of companies are verifiable, the authors contend that as we speak’s LLM platforms function underneath structural opacity: customers are charged primarily based on reported token and API utilization, however don’t have any means to substantiate that these metrics replicate actual or mandatory work.
The paper identifies two key types of manipulation: amount inflation, the place the variety of tokens or calls is elevated with out person profit; and high quality downgrade, the place lower-performing fashions or instruments are silently used instead of premium parts:
‘In reasoning LLM APIs, suppliers typically keep a number of variants of the identical mannequin household, differing in capability, coaching knowledge, or optimization technique (e.g., ChatGPT o1, o3). Mannequin downgrade refers back to the silent substitution of lower-cost fashions, which can introduce misalignment between anticipated and precise service high quality.
‘For instance, a immediate could also be processed by a smaller-sized mannequin, whereas billing stays unchanged. This observe is tough for customers to detect, as the ultimate reply should seem believable for a lot of duties.’
The paper paperwork situations the place greater than ninety % of billed tokens have been by no means proven to customers, with inner reasoning inflating token utilization by an element better than twenty. Justified or not, the opacity of those steps denies customers any foundation for evaluating their relevance or legitimacy.
In agentic techniques, the opacity will increase, as inner exchanges between AI brokers can every incur fees with out meaningfully affecting the ultimate output:
‘Past inner reasoning, brokers talk by exchanging prompts, summaries, and planning directions. Every agent each interprets inputs from others and generates outputs to information the workflow. These inter-agent messages could eat substantial tokens, which are sometimes indirectly seen to finish customers.
‘All tokens consumed throughout agent coordination, together with generated prompts, responses, and tool-related directions, are usually not surfaced to the person. When the brokers themselves use reasoning fashions, billing turns into much more opaque’
To confront these points, the authors suggest a layered auditing framework involving cryptographic proofs of inner exercise, verifiable markers of mannequin or software identification, and impartial oversight. The underlying concern, nevertheless, is structural: present LLM billing schemes depend upon a persistent asymmetry of data, leaving customers uncovered to prices that they can’t confirm or break down.
Counting the Invisible
The ultimate paper, from researchers on the College of Maryland, re-frames the billing downside not as a query of misuse or misreporting, however of construction. The paper – titled CoIn: Counting the Invisible Reasoning Tokens in Industrial Opaque LLM APIs, and from ten researchers on the College of Maryland – observes that the majority industrial LLM companies now cover the intermediate reasoning that contributes to a mannequin’s closing reply, but nonetheless cost for these tokens.
The paper asserts that this creates an unobservable billing floor the place whole sequences could be fabricated, injected, or inflated with out detection*:
‘[This] invisibility permits suppliers to misreport token counts or inject low-cost, fabricated reasoning tokens to artificially inflate token counts. We seek advice from this observe as token depend inflation.
‘As an example, a single high-efficiency ARC-AGI run by OpenAI’s o3 mannequin consumed 111 million tokens, costing $66,772.3 Given this scale, even small manipulations can result in substantial monetary impression.
‘Such info asymmetry permits AI firms to considerably overcharge customers, thereby undermining their pursuits.’
To counter this asymmetry, the authors suggest CoIn, a third-party auditing system designed to confirm hidden tokens with out revealing their contents, and which makes use of hashed fingerprints and semantic checks to identify indicators of inflation.

Overview of the CoIn auditing system for opaque industrial LLMs. Panel A reveals how reasoning token embeddings are hashed right into a Merkle tree for token depend verification with out revealing token contents. Panel B illustrates semantic validity checks, the place light-weight neural networks examine reasoning blocks to the ultimate reply. Collectively, these parts permit third-party auditors to detect hidden token inflation whereas preserving the confidentiality of proprietary mannequin conduct. Supply: https://arxiv.org/pdf/2505.13778
One element verifies token counts cryptographically utilizing a Merkle tree; the opposite assesses the relevance of the hidden content material by evaluating it to the reply embedding. This permits auditors to detect padding or irrelevance – indicators that tokens are being inserted merely to hike up the invoice.
When deployed in checks, CoIn achieved a detection success price of practically 95% for some types of inflation, with minimal publicity of the underlying knowledge. Although the system nonetheless will depend on voluntary cooperation from suppliers, and has restricted decision in edge instances, its broader level is unmistakable: the very structure of present LLM billing assumes an honesty that can not be verified.
Conclusion
Moreover the benefit of gaining pre-payment from customers, a scrip-based forex (such because the ‘buzz’ system at CivitAI) helps to summary customers away from the true worth of the forex they’re spending, or the commodity they’re shopping for. Likewise, giving a vendor leeway to outline their personal items of measurement additional leaves the buyer at nighttime about what they’re really spending, by way of actual cash.
Just like the lack of clocks in Las Vegas, measures of this sort are sometimes aimed toward making the buyer reckless or detached to value.
The scarcely-understood token, which could be consumed and outlined in so some ways, is maybe not an appropriate unit of measurement for LLM consumption – not least as a result of it could actually value many instances extra tokens to calculate a poorer LLM end in a non-English language, in comparison with an English-based session.
Nevertheless, character-based output, as advised by the Max Planck researchers, would possible favor extra concise languages and penalize naturally verbose languages. Since visible indications comparable to a depreciating token counter would in all probability make us somewhat extra spendthrift in our LLM periods, it appears unlikely that such helpful GUI additions are coming anytime quickly – a minimum of with out legislative motion.
* Authors’ emphases. My conversion of the authors’ inline citations to hyperlinks.
First printed Thursday, Could 29, 2025






{kind=link}