



























Final month, we launched Gemma 3, our newest technology of open fashions. Delivering state-of-the-art efficiency, Gemma 3 rapidly established itself as a number one mannequin able to operating on a single high-end GPU just like the NVIDIA H100 utilizing its native BFloat16 (BF16) precision.
To make Gemma 3 much more accessible, we’re asserting new variations optimized with Quantization-Conscious Coaching (QAT) that dramatically reduces reminiscence necessities whereas sustaining prime quality. This allows you to run highly effective fashions like Gemma 3 27B domestically on consumer-grade GPUs just like the NVIDIA RTX 3090.
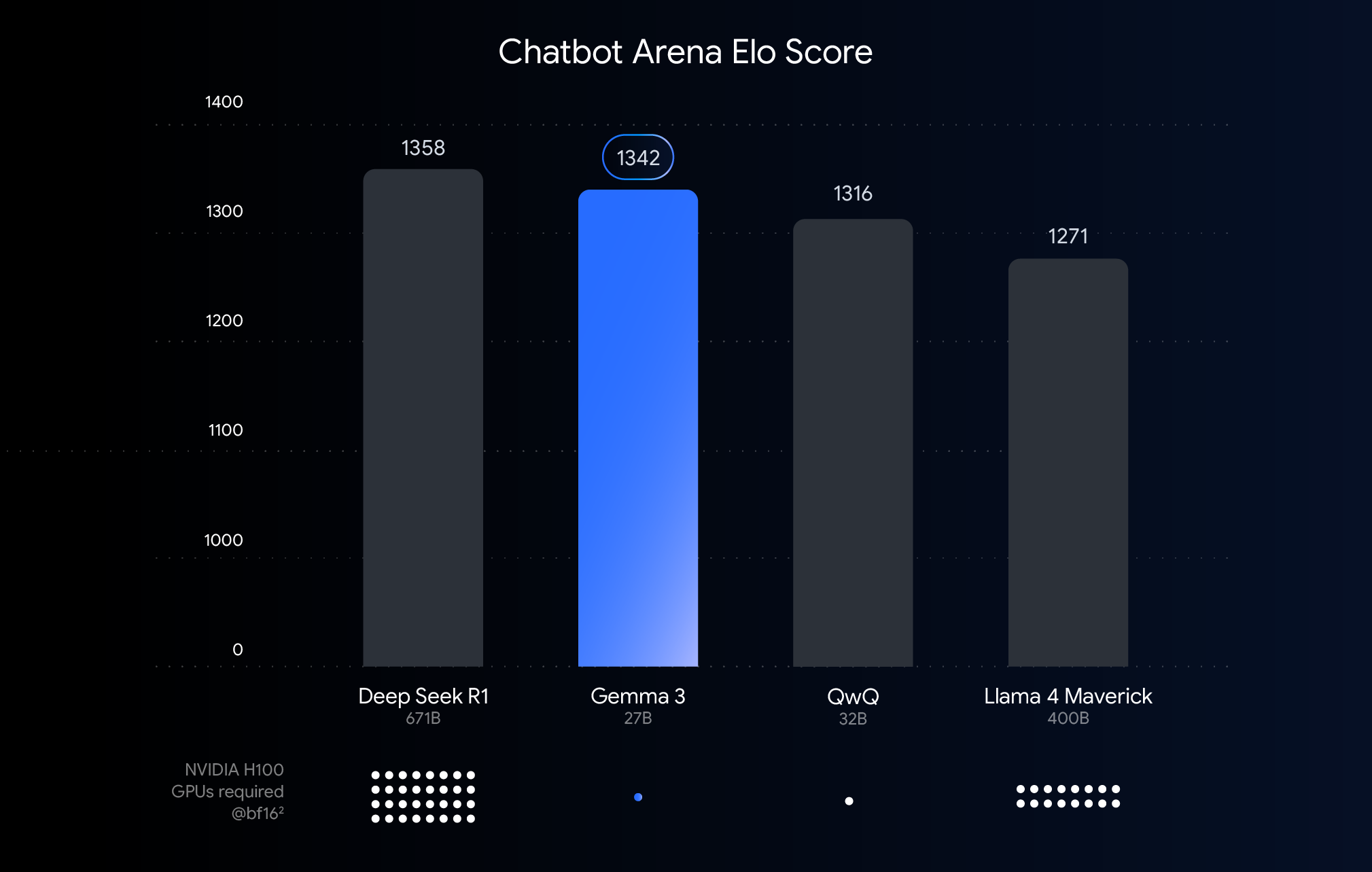
This chart ranks AI fashions by Chatbot Enviornment Elo scores; larger scores (high numbers) point out larger consumer desire. Dots present estimated NVIDIA H100 GPU necessities.
Understanding efficiency, precision, and quantization
The chart above exhibits the efficiency (Elo rating) of just lately launched giant language fashions. Greater bars imply higher efficiency in comparisons as rated by people viewing side-by-side responses from two nameless fashions. Beneath every bar, we point out the estimated variety of NVIDIA H100 GPUs wanted to run that mannequin utilizing the BF16 knowledge kind.
Why BFloat16 for this comparability? BF16 is a typical numerical format used throughout inference of many giant fashions. It signifies that the mannequin parameters are represented with 16 bits of precision. Utilizing BF16 for all fashions helps us to make an apples-to-apples comparability of fashions in a typical inference setup. This permits us to check the inherent capabilities of the fashions themselves, eradicating variables like completely different {hardware} or optimization methods like quantization, which we’ll talk about subsequent.
It is essential to notice that whereas this chart makes use of BF16 for a good comparability, deploying the very largest fashions typically entails utilizing lower-precision codecs like FP8 as a sensible necessity to cut back immense {hardware} necessities (just like the variety of GPUs), doubtlessly accepting a efficiency trade-off for feasibility.
The Want for Accessibility
Whereas high efficiency on high-end {hardware} is nice for cloud deployments and analysis, we heard you loud and clear: you need the ability of Gemma 3 on the {hardware} you already personal. We’re dedicated to creating highly effective AI accessible, and which means enabling environment friendly efficiency on the consumer-grade GPUs present in desktops, laptops, and even telephones.
Efficiency Meets Accessibility with Quantization-Conscious Coaching in Gemma 3
That is the place quantization is available in. In AI fashions, quantization reduces the precision of the numbers (the mannequin’s parameters) it shops and makes use of to calculate responses. Consider quantization like compressing a picture by lowering the variety of colours it makes use of. As an alternative of utilizing 16 bits per quantity (BFloat16), we will use fewer bits, like 8 (int8) and even 4 (int4).
Utilizing int4 means every quantity is represented utilizing solely 4 bits – a 4x discount in knowledge dimension in comparison with BF16. Quantization can typically result in efficiency degradation, so we’re excited to launch Gemma 3 fashions which are sturdy to quantization. We launched a number of quantized variants for every Gemma 3 mannequin to allow inference together with your favourite inference engine, akin to Q4_0 (a typical quantization format) for Ollama, llama.cpp, and MLX.
How will we keep high quality? We use QAT. As an alternative of simply quantizing the mannequin after it is totally skilled, QAT incorporates the quantization course of throughout coaching. QAT simulates low-precision operations throughout coaching to permit quantization with much less degradation afterwards for smaller, quicker fashions whereas sustaining accuracy. Diving deeper, we utilized QAT on ~5,000 steps utilizing chances from the non-quantized checkpoint as targets. We cut back the perplexity drop by 54% (utilizing llama.cpp perplexity analysis) when quantizing all the way down to Q4_0.
See the Distinction: Large VRAM Financial savings
The impression of int4 quantization is dramatic. Take a look at the VRAM (GPU reminiscence) required simply to load the mannequin weights:
- Gemma 3 27B: Drops from 54 GB (BF16) to simply 14.1 GB (int4)
- Gemma 3 12B: Shrinks from 24 GB (BF16) to solely 6.6 GB (int4)
- Gemma 3 4B: Reduces from 8 GB (BF16) to a lean 2.6 GB (int4)
- Gemma 3 1B: Goes from 2 GB (BF16) all the way down to a tiny 0.5 GB (int4)
Be aware: This determine solely represents the VRAM required to load the mannequin weights. Operating the mannequin additionally requires extra VRAM for the KV cache, which shops details about the continued dialog and relies on the context size
Run Gemma 3 on Your Machine
These dramatic reductions unlock the power to run bigger, highly effective fashions on broadly accessible shopper {hardware}:
- Gemma 3 27B (int4): Now matches comfortably on a single desktop NVIDIA RTX 3090 (24GB VRAM) or related card, permitting you to run our largest Gemma 3 variant domestically.
- Gemma 3 12B (int4): Runs effectively on laptop computer GPUs just like the NVIDIA RTX 4060 Laptop computer GPU (8GB VRAM), bringing highly effective AI capabilities to transportable machines.
- Smaller Fashions (4B, 1B): Supply even larger accessibility for methods with extra constrained sources, together with telephones and toasters (when you’ve got an excellent one).
Simple Integration with Widespread Instruments
We wish you to have the ability to use these fashions simply inside your most well-liked workflow. Our official int4 and Q4_0 unquantized QAT fashions can be found on Hugging Face and Kaggle. We’ve partnered with standard developer instruments that allow seamlessly making an attempt out the QAT-based quantized checkpoints:
- Ollama: Get operating rapidly – all our Gemma 3 QAT fashions are natively supported beginning at the moment with a easy command.
- LM Studio: Simply obtain and run Gemma 3 QAT fashions in your desktop by way of its user-friendly interface.
- MLX: Leverage MLX for environment friendly, optimized inference of Gemma 3 QAT fashions on Apple Silicon.
- Gemma.cpp: Use our devoted C++ implementation for extremely environment friendly inference instantly on the CPU.
- llama.cpp: Combine simply into present workflows because of native help for our GGUF-formatted QAT fashions.
Extra Quantizations within the Gemmaverse
Our official Quantization Conscious Skilled (QAT) fashions present a high-quality baseline, however the vibrant Gemmaverse presents many options. These typically use Publish-Coaching Quantization (PTQ), with vital contributions from members akin to Bartowski, Unsloth, and GGML available on Hugging Face. Exploring these group choices offers a wider spectrum of dimension, velocity, and high quality trade-offs to suit particular wants.
Get Began At this time
Bringing state-of-the-art AI efficiency to accessible {hardware} is a key step in democratizing AI improvement. With Gemma 3 fashions, optimized via QAT, now you can leverage cutting-edge capabilities by yourself desktop or laptop computer.
Discover the quantized fashions and begin constructing:
We won’t wait to see what you construct with Gemma 3 operating domestically!




{kind=link}