






























Synthetic intelligence has made outstanding strides with the event of Giant Language Fashions (LLMs), considerably impacting numerous domains, together with pure language processing, reasoning, and even coding duties. As LLMs develop extra highly effective, they require refined strategies to optimize their efficiency throughout inference. Inference-time strategies and methods used to enhance the standard of responses generated by these fashions at runtime have change into essential. Nonetheless, the analysis neighborhood should nonetheless set up finest practices for integrating these strategies right into a cohesive system.
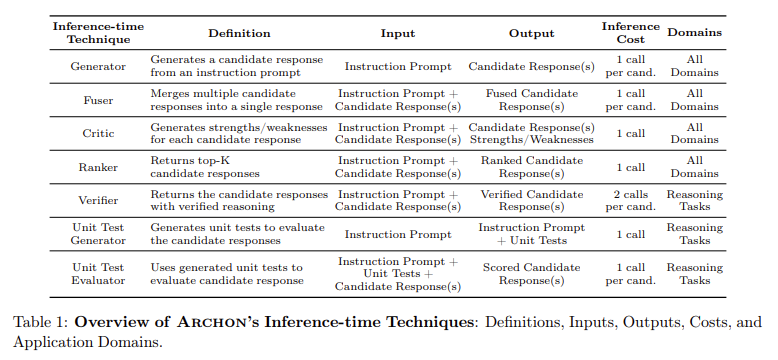
A core problem in bettering LLM efficiency is figuring out which inference-time strategies yield the perfect outcomes for various duties. The issue is compounded by the sheer number of capabilities, reminiscent of instruction-following, reasoning, and coding, which can profit from numerous mixtures of inference-time strategies. Furthermore, understanding the advanced interactions between strategies like ensembling, repeated sampling, rating, fusion, and verification is essential for maximizing efficiency. Researchers want a strong system that may effectively discover the in depth design house of attainable mixtures and optimize these architectures in accordance with the duty and compute constraints.
Conventional strategies for inference-time optimization have targeted on making use of particular person strategies to LLMs. For example, era ensembling entails querying a number of fashions concurrently and choosing the right response, whereas repeated sampling entails querying a single mannequin quite a few occasions. These strategies have proven promise, however their standalone software typically results in restricted enhancements. Frameworks like Combination-of-Brokers (MoA) and LeanStar have tried to combine a number of strategies however nonetheless face challenges in generalization and efficiency throughout numerous duties. Thus, there’s a rising demand for a modular, automated method to constructing optimized LLM techniques.
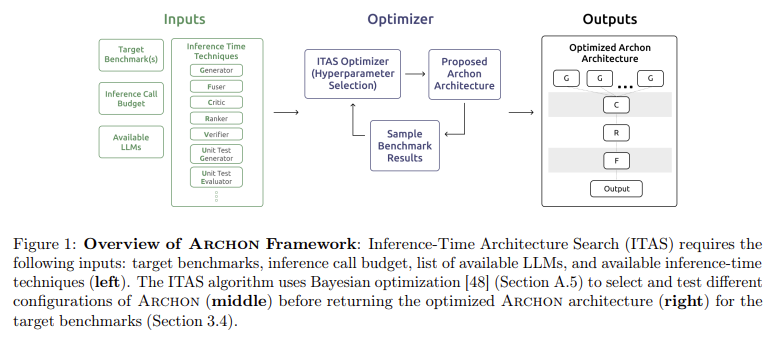
Researchers from Stanford College and the College of Washington have developed Archon, a modular framework designed to automate LLM structure search utilizing inference-time strategies. The Archon framework leverages various LLMs and inference-time strategies, combining them right into a cohesive system that surpasses conventional fashions’ efficiency. Reasonably than counting on a single LLM queried as soon as, Archon dynamically selects, combines, and stacks layers of strategies to optimize efficiency for particular benchmarks. By treating the issue as a hyperparameter optimization activity, the framework can establish optimum architectures that maximize accuracy, latency, and cost-efficiency for a given compute price range.
The Archon framework is structured as a multi-layered system the place every layer performs a definite inference-time method. For instance, the primary layer would possibly generate a number of candidate responses utilizing an ensemble of LLMs, whereas subsequent layers apply rating, fusion, or verification strategies to refine these responses. The framework makes use of Bayesian optimization algorithms to look potential configurations and choose the best one for a goal benchmark. This modular design permits Archon to outperform top-performing fashions like GPT-4o and Claude 3.5 Sonnet by a mean of 15.1 share factors throughout a variety of duties.
The efficiency of Archon was evaluated throughout a number of benchmarks, together with MT-Bench, Enviornment-Arduous-Auto, AlpacaEval 2.0, MixEval, MixEval Arduous, MATH, and CodeContests. The outcomes have been compelling: Archon architectures demonstrated a mean accuracy improve of 11.2 share factors utilizing open-source fashions and 15.1 share factors using a mixture of open-source and closed-source fashions. In coding duties, the framework achieved a 56% enchancment in Go@1 scores, boosting accuracy from 17.9% to 29.3% by means of unit take a look at era and analysis. Even when constrained to open-source fashions, Archon surpassed the efficiency of single-call state-of-the-art fashions by 11.2 share factors, highlighting the efficacy of its layered method.
The important thing outcomes present that Archon achieves state-of-the-art efficiency in numerous domains by integrating a number of inference-time strategies. For instruction-following duties, including quite a few layers of era, rating, and fusion considerably improved the standard of responses. Archon excelled in reasoning duties like MixEval and MATH by incorporating verification and unit testing strategies, resulting in a mean improve of three.7 to eight.9 share factors when making use of task-specific architectures. The framework mixed in depth sampling and unit take a look at era to supply correct and dependable outputs for coding challenges.
Key Takeaways from the analysis on Archon:
- Efficiency Increase: Archon achieves a mean accuracy improve of 15.1 share factors throughout numerous benchmarks, outperforming state-of-the-art fashions like GPT-4o and Claude 3.5 Sonnet.
- Various Functions: The framework excels in instruction-following, reasoning, and coding duties, displaying versatility.
- Efficient Inference-Time Strategies: Archon gives superior efficiency in all evaluated eventualities by combining strategies reminiscent of ensembling, fusion, rating, and verification.
- Improved Coding Accuracy: Achieved a 56% enhance in coding activity accuracy by leveraging unit take a look at era and analysis strategies.
- Scalability and Modularity: The framework’s modular design permits it to adapt simply to new duties and configurations, making it a strong device for LLM optimization.

In conclusion, Archon addresses the vital want for an automatic system that optimizes LLMs at inference time by successfully combining numerous strategies. This analysis gives a sensible resolution to the complexities of inference-time structure design, making it simpler for builders to construct high-performing LLM techniques tailor-made to particular duties. The Archon framework units a brand new customary for optimizing LLMs. It gives a scientific and automatic method to inference-time structure search, demonstrating its means to realize top-tier outcomes throughout various benchmarks.
Take a look at the Paper and GitHub. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. In the event you like our work, you’ll love our publication.. Don’t Overlook to affix our 50k+ ML SubReddit
[Upcoming Event- Oct 17 202] RetrieveX – The GenAI Knowledge Retrieval Convention (Promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its recognition amongst audiences.






{kind=link}