





























Artificial intelligence (AI) has made significant strides in recent years, especially with the development of large-scale language models. These models, trained on massive datasets like internet text, have shown impressive abilities in knowledge-based tasks such as answering questions, summarizing content, and understanding instructions. However, despite their success, these models need help regarding specialized domains where data is scarce or highly specific. Training these models to perform well in niche areas remains a significant hurdle, with only a small amount of text available.
A central problem in AI research is the inefficient way models acquire knowledge from small datasets. Current models need exposure to thousands of variations of the same fact to learn it effectively. This poses a problem when a fact appears only once or twice in a specialized corpus, making it difficult for models to understand and generalize from such limited information. This inefficiency is even more pronounced when adapting a general language model to a new, domain-specific field where diverse representations of key concepts are absent.
Current AI methods attempt to address this issue through pretraining on massive datasets, which gives models a broad understanding of general topics. However, this approach is ineffective for domains with only a small corpus of information. Some researchers have tried to solve this by paraphrasing the original text multiple times to create diverse representations. However, this method, though straightforward, needs more ability to introduce new perspectives or deepen understanding. After a few rounds of rephrasing, the model’s performance tends to plateau, as rephrasing alone does not provide enough variation for significant learning improvements.
Researchers from Stanford University introduced EntiGraph, an innovative approach to solving this problem through synthetic data generation. The team, comprised of members from the Department of Statistics and the Department of Computer Science, developed EntiGraph to generate a large, synthetic corpus from a small, domain-specific dataset. The goal is to help models learn more effectively by providing a greater diversity of examples. EntiGraph identifies key entities within the original text and then uses a language model to generate new, varied content around the relationships between these entities. This method enables the creation of a diverse training set, even from a small amount of data.
EntiGraph begins by extracting important entities from a given dataset. Entities can be people, places, or concepts central to the text. After identifying these entities, the algorithm uses a language model to describe their relationships. These descriptions are then combined into a synthetic dataset that expands the original corpus, providing the language model with a much larger and richer training data set. This process allows the language model to learn connections between entities in ways not present in the original text, leading to better knowledge acquisition. Furthermore, EntiGraph organizes these relationships into a knowledge graph, which enables further exploration of how different entities interact within the dataset.
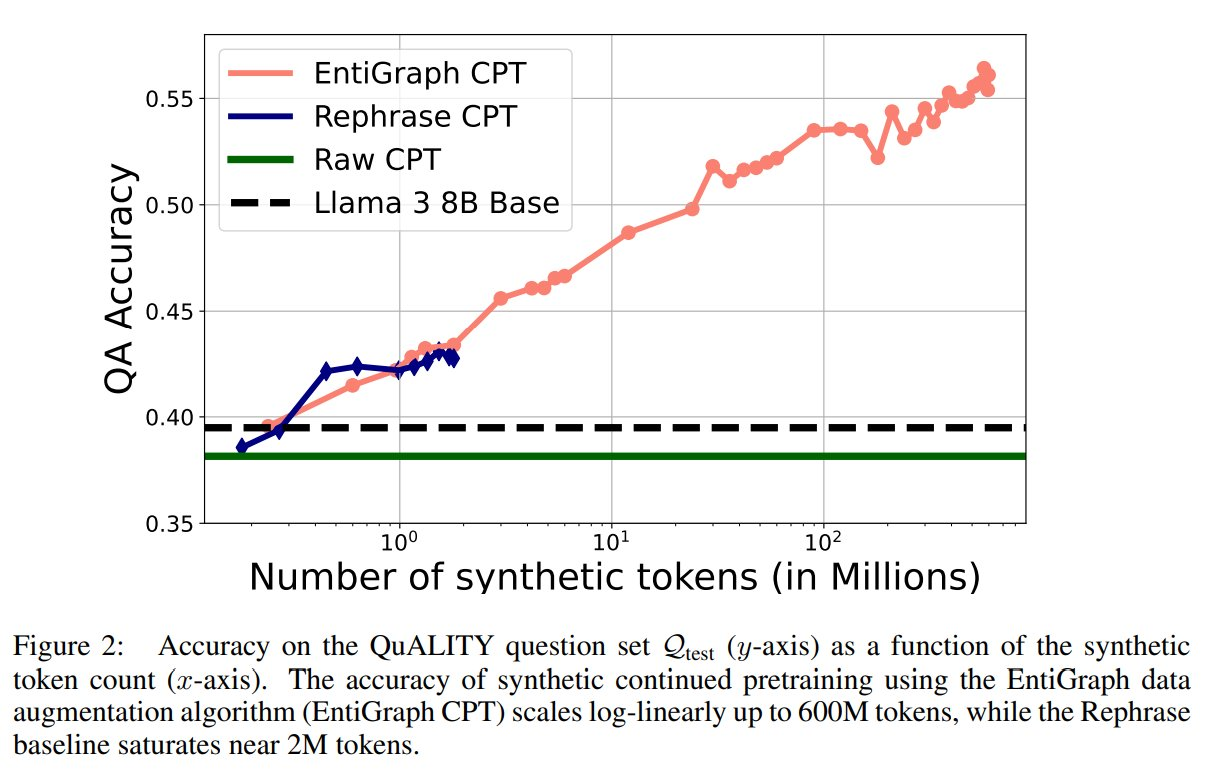
The performance of EntiGraph was tested in a series of experiments, and the results were promising. The researchers took a corpus of 1.3 million tokens and used EntiGraph to generate a synthetic dataset containing 600 million tokens. They then pretrained a language model, Llama 3 8B, on this larger dataset. The results showed a log-linear improvement in accuracy as the number of synthetic tokens increased. For instance, the model’s accuracy in question-answering tasks improved from 39.49% when using the original dataset to 56.42% after pretraining on the synthetic corpus. Moreover, the synthetic pretraining using EntiGraph provided up to 80% of the accuracy boost that models achieve when they can access the original documents during inference. This shows that even without access to the original data, models can perform well after training on a synthetic corpus.
The study also revealed that EntiGraph outperforms existing methods, such as simply rephrasing the dataset. In one comparison, the rephrased corpus contained only 1.8 million tokens, and the model’s accuracy plateaued at 43.08%. In contrast, EntiGraph improved model performance even as the synthetic dataset grew to 600 million tokens. The ability to synthesize larger and more diverse datasets allowed for more effective knowledge transfer, demonstrating the superiority of this method in enabling language models to learn from small, specialized datasets.
In conclusion, the introduction of EntiGraph marks a significant advancement in addressing the challenges of data efficiency in AI models. The method successfully generates a diverse, synthetic corpus from a small dataset, enabling models to acquire domain-specific knowledge more effectively. This research highlights a novel approach that could lead to further developments in AI training techniques, particularly for specialized fields where data is limited. The results show that EntiGraph provides a viable solution to overcoming the limitations of existing methods, allowing language models to better adapt to niche domains and perform complex tasks with improved accuracy.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.






{kind=link}